Overview
Aptible Apps are scaled at the Service level, meaning each App Service is scaled independently. App Services can be scaled by adding more CPU/RAM (vertical scaling) or by adding more containers (horizontal). App Services can be scaled manually via the CLI or UI, automatically with the Autoscaling, or programmatically with Terraform. Apps with more than two containers are deployed in a high-availability configuration, ensuring redundancy across different zones. When Apps are scaled, a new set of containers will be launched to replace the existing ones for each of your App’s Services.High-availability Apps
Apps scaled to 2 or more Containers are automatically deployed in a high-availability configuration, with Containers deployed in separate AWS Availability Zones.Horizontal Scaling
Scale Apps horizontally by adding more Containers to a given Service. Each App Service can scale up to 32 Containers via the Aptible Dashboard. Scaling above 32 containers for a service (with a maximum of 128 containers) is supported via the Aptible CLI and the Aptible Terraform Provider.Services with an attached Persistent Disk cannot be scaled horizontally. They must run on exactly one Container.
Manual Horizontial Scaling
App Services can be manually scaled via the Dashboard oraptible apps:scale CLI command. Example:
Horizontal Autoscaling
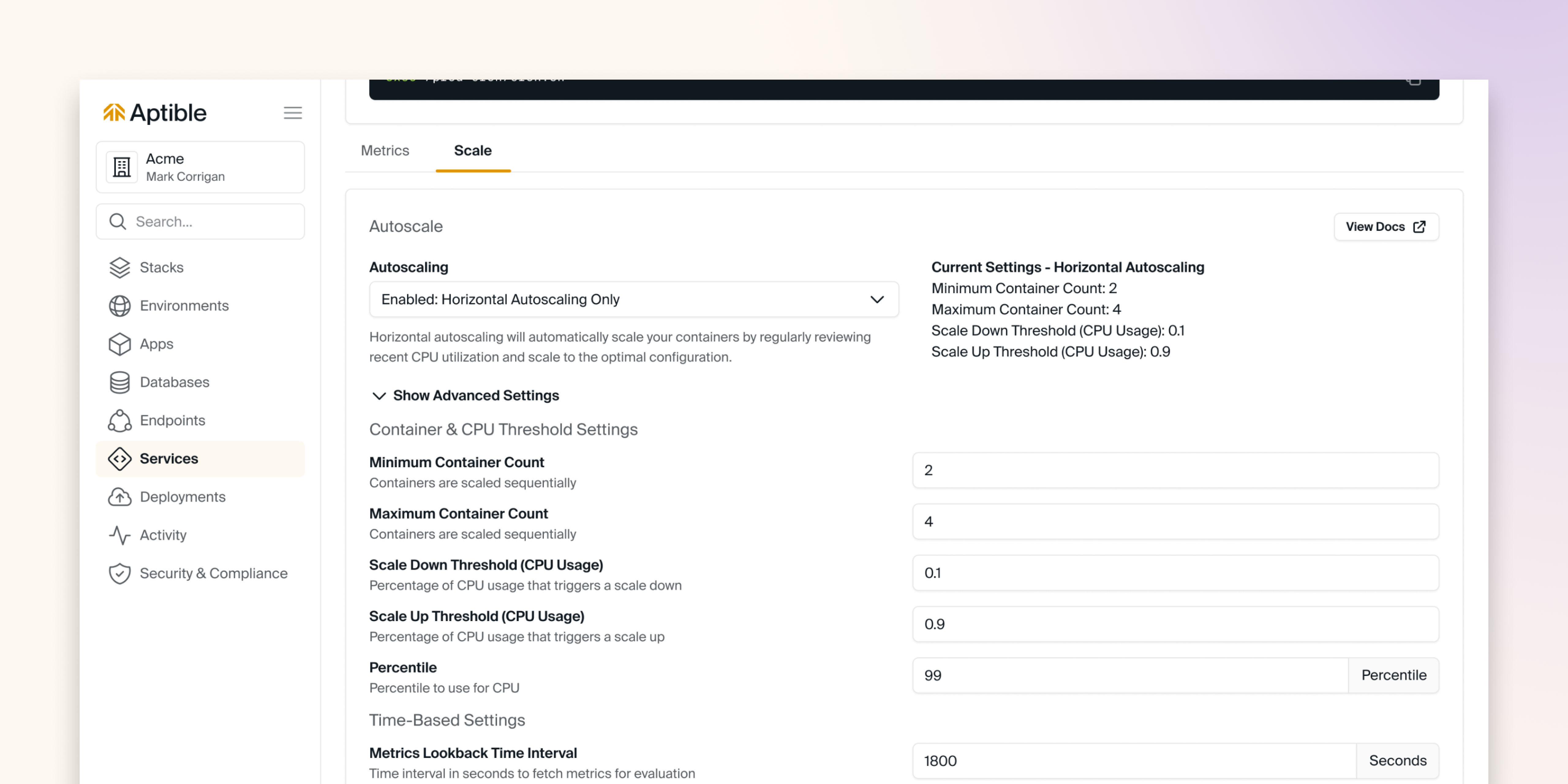
Horizontal Autoscaling is only available on the Production and Enterprise plans.
aptible services:autoscaling_policy:set CLI command.
By default, a Horizontal Autoscaling Operation follows the regular Container Lifecycle and Releases pattern of restarting all current containers when modifying the number of running containers. However, this behavior can be disabled by enabling the Restart Free Scaling (use_horizontal_scale in Terraform) setting when configuring autoscaling for the service. With restart free scaling enabled, containers are added and removed without restarting the existing ones. When removing containers in this configuration, the service’s stop timeout is still respected. Note that if the service has a TCP, TLS, or GRPC endpoint, the regular full restart will still occur even with restart free scaling enabled. Additionally, if any endpoint associated with the service failed its most recent provision operation (which is an operation that is called on create of a new endpoint, or update of an existing endpoint), the regular full restart will still occur even with restart free scaling enabled.
Guide for Configuring Horizontial Autoscaling
Configuration Options
Container & CPU Threshold Settings
Container & CPU Threshold Settings
The following container & CPU threshold settings are available for configuration:
CPU thresholds are expressed as a number between 0 and 1, reflecting the actual percentage usage of your container’s CPU limit. For instance, 2% usage with a 12.5% limit equals 16%, or 0.16.
- Percentile: Determines the percentile for evaluating RAM and CPU usage.
- Minimum Container Count: Sets the lowest container count to which the service can be scaled down by Autoscaler.
- Maximum Container Count: Sets the highest container count to which the service can be scaled up to by Autoscaler.
- Scale Up Steps: Sets the amount of containers to add when autoscaling (ex: a value of 2 will go from 1->3->5). Container count will never exceed the configured maximum.
- Scale Down Steps: Sets the amount of containers to remove when autoscaling (ex: a value of 2 will go from 4->2->1). Container count will never exceed the configured minimum.
- Scale Down Threshold (CPU Usage): Specifies the percentage of the current CPU usage at which an up-scaling action is triggered.
- Scale Up Threshold (CPU Usage): Specifies the percentage of the current CPU usage at which a down-scaling action is triggered.
Time-Based Settings
Time-Based Settings
The following time-based settings are available for configuration:
- Metrics Lookback Time Interval: The duration in seconds for retrieving past performance metrics.
- Post Scale Up Cooldown: The waiting period in seconds after an automated scale-up before another scaling action can be considered. The period of time the service is on cooldown is still considered in the metrics for the next potential scale.
- Post Scale Down Cooldown: The waiting period in seconds after an automated scale-down before another scaling action can be considered. The period of time the service is on cooldown is still considered in the metrics for the next potential scale.
- Post Release Cooldown: The time in seconds to ignore following any general scaling operation, allowing stabilization before considering additional scaling changes. For this metric, the cooldown period is not considered in the metrics for the next potential scale.
General Settings
General Settings
The following general settings are available for configuration:
- Restart Free Scaling: When enabled, scale operations for modifying the number of running containers will not restart the other containers in the service.
Vertical Scaling
Scale Apps vertically by changing the size of Containers, i.e., changing their Memory Limits and CPU Limits. The available sizes are determined by the Container Profile.Manual Vertical Scaling
App Services can be manually scaled via the Dashboard oraptible apps:scale CLI command. Example:
Vertical Autoscaling
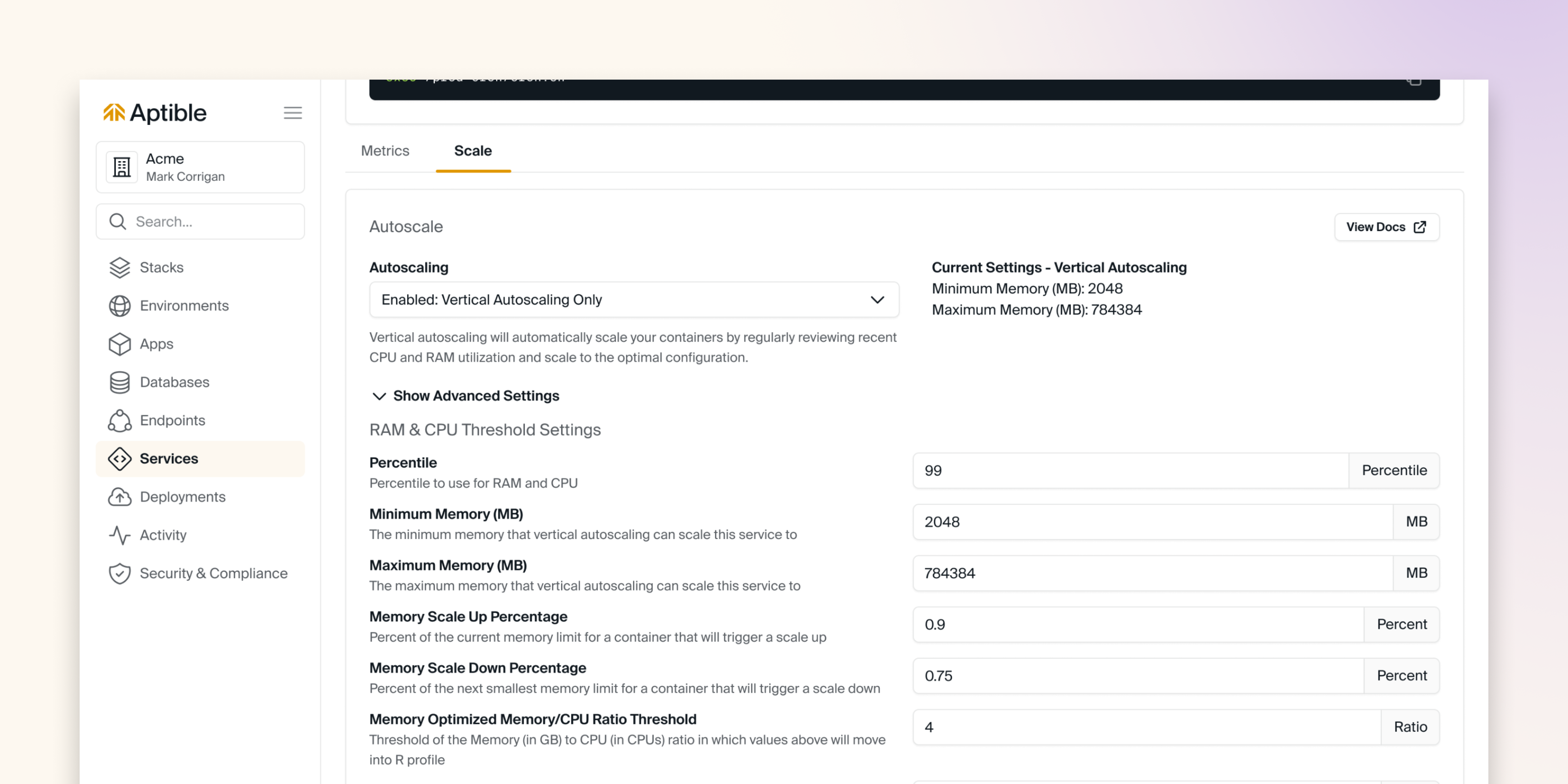
Vertical Autoscaling is only available on the Enterprise plan.
- RSS usage in GB divided by the CPU
- RSS usage levels
aptible services:autoscaling_policy:set CLI command.
Configuration Options
RAM & CPU Threshold Settings
RAM & CPU Threshold Settings
The following RAM & CPU Threshold settings are available for configuration:
- Percentile: Sets the percentile of current RAM and CPU usage to use when evaluating autoscaling actions.
- Minimum Memory (MB): Sets the lowest container size the service can be scaled down to.
- Maximum Memory (MB): Sets the highest container size the service can be scaled up to. If blank, the container can scale to the largest size available.
- Memory Scale Up Percentage: Specifies a threshold based on a percentage of the current memory limit at which the service’s memory usage triggers a scale up.
- Memory Scale Down Percentage: Specifies a threshold based on the percentage of the next smallest container size’s memory limit at which the service’s memory usage triggers a scale down.
- Memory Optimized Memory/CPU Ratio Threshold: Establishes the ratio of Memory (in GB) to CPU (in CPUs) at which values exceeding the threshold prompt a shift to an R (Memory Optimized) profile.
- Compute Optimized Memory/CPU Ratio Threshold: Sets the Memory-to-CPU ratio threshold, below which the service is transitioned to a C (Compute Optimized) profile.
Time-Based Settings
Time-Based Settings
The following time-based settings are available for configuration:
- Metrics Lookback Time Interval: The duration in seconds for retrieving past performance metrics.
- Post Scale Up Cooldown: The waiting period in seconds after an automated scale-up before another scaling action can be considered. The period of time the service is on cooldown is still considered in the metrics for the next potential scale.
- Post Scale Down Cooldown: The waiting period in seconds after an automated scale-down before another scaling action can be considered. The period of time the service is on cooldown is still considered in the metrics for the next potential scale.
- Post Release Cooldown: The time in seconds to ignore following any general scaling operation, allowing stabilization before considering additional scaling changes. For this metric, the cooldown period is not considered in the metrics for the next potential scale.
FAQ
How do I scale my apps and services?
How do I scale my apps and services?
See our guide here for How to scale apps and services